Terminology Evolution in Web Archiving: Open Issues
Terminology Evolution in Web Archiving: Open Issues
Abstract
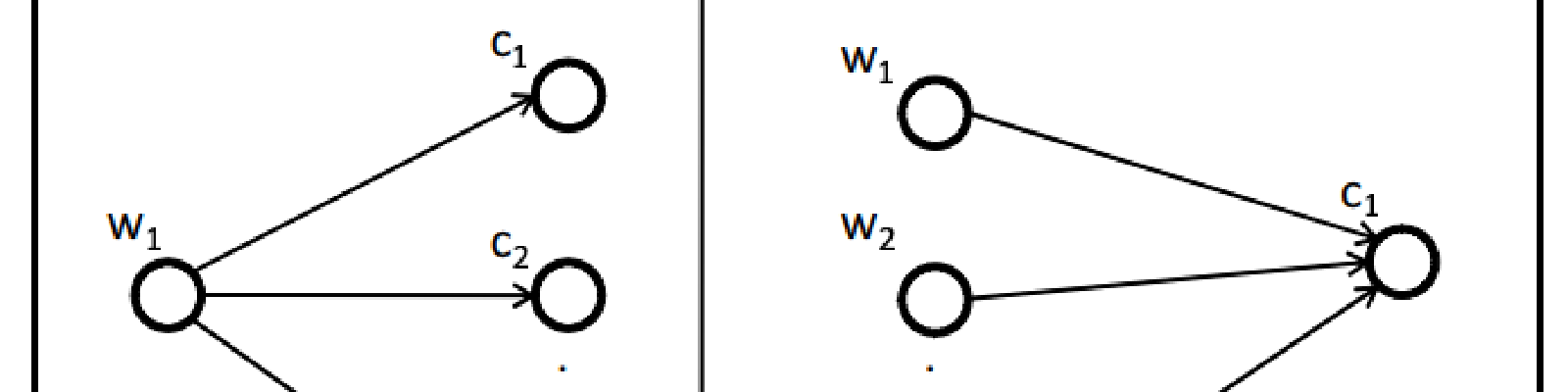
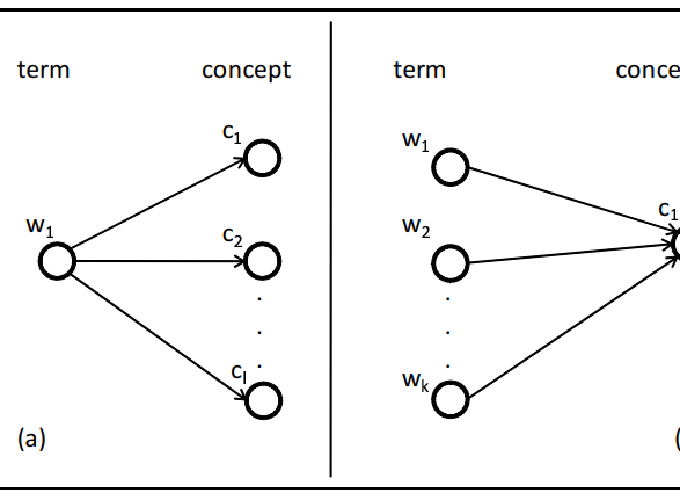
The correspondence between the terminology used for querying and the one used in content objects to be retrieved, is a crucial prerequisite for effective retrieval technology. How- ever, as terminology is evolving over time, a growing gap opens up between older documents in (long-term) archives and the active language used for querying such archives. Thus, technologies for detecting and systematically handling terminology evolution are required to ensure semantic accessibility of (Web) archive content on the long run. As a starting point for dealing with terminology evolution this paper formalizes the problem and discusses issues, first ideas and relevant technologies.
Type
Publication
In the 8th International Web Archiving Workshop, IWAW 2008
Date
August, 2008
Links