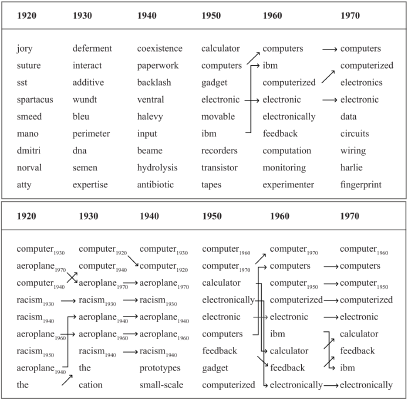
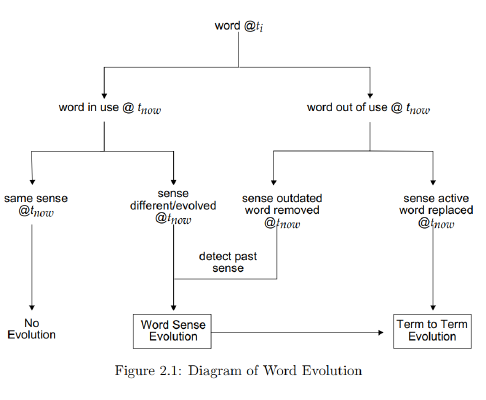
The most common word for ‘young female human’ changed from maiden in Old and Middle English to girl in Modern English. This is a case of lexical replacement: a bundle of semantic material is first symbolized by one word, and later in time by another word (onomasiology). Parallel to this, girl ‘young person’ came to mean ‘young female person’. This is a case of semantic change: a word stays the same over time 1 while the semantic material it symbolizes changes (semasiology). It is often useful to talk about the semantic material of a word as clustering into several sub-meanings: senses. Senses can be added, removed or changed. A particularly interesting kind of alteration is positive/negative sentiment change: while the morpheme skit in skitdag ’shitty, bad day’ has a negative connotation, in the last few decades it has acquired a positive connotation as an intensifier in words like skitgott ’really good’. Sentiment analysis is increasingly important for commercial and political research and can greatly benefit from automatically handling lexical and semantic change.
All these intertwined processes make lexical and semantic change highly complex problems relying on defining a particular sense (and the allocation of senses to words), problems that are considered AI complete, i.e. equivalent of making computers as intelligent as people. Recent NLP advances based on the distributional hypothesis of meaning have proven extremely useful in assisting researchers in untangling SC processes. The distributional hypothesis links semantic similarity to distributional similarity - meaning can be induced from the set of words that appear in similar contexts. Automatically induced senses are approximations of an underlying word sense and vary naturally depending on which sentences that are used for the sense induction. A great challenge in automatic change detection is determining when two induced senses (for the same word at different times) are natural variations and when the differences represent sense change (cf okasionelle and usuelle Bedeutung in Paul (1886)).
The methods developed in this project will go beyond the state-of-the-art in the field in several aspects. Previously, Semantic Change detection projects have primarily focused on (i) a limited number of change types, e.g., only birth of senses; (ii) a few (far apart) time points, e.g., 50-year slots; or (iii) methods that find signals for change without differentiating between change types or separating the senses of a word (i.e., one topic/vector/cluster per word); and (iv) words in isolation, not their interplay within a semantic field. Existing techniques reduce complexity severely because considering yearly time buckets over two centuries and up to 5 senses per time period, the solution space is in the order of 5200 which is impossible to compute and evaluate. This project will build on the promising reduction techniques described by Tahmasebi and Risse (2017) to enable us to answer the what, how and when questions in full, and create a complete picture of all changes related to a word and its semantic field.
For automatic Lexical Replacement, we will set the state-of-the-art simply because there is almost no existing research. The problem is extremely complex because words must be linked based on their (stable) senses. In this project, we have a unique opportunity to study the LR problem because we are one of few research groups that will attempt to solve the problem of word sense change first. We will beginby working on word sense induction for Swedish, as this is the core of our methodology. Once we can induce word senses automatically, we can begin to detect change in senses (SC) and then, as a third step, find word replacement (LR). Using these tools, we can study the varying speed and different processes of LR and SC in e.g. different parts of the vocabulary and during different time periods. Thus far, methods for detecting sentiment change, i.e., words changing their sentiment value, (Cook and Stevenson, 2010; Nguyen et al., 2012) have not differentiated between different senses: only the predominant value of a word has been considered. We will be able to overcome this hurdle by first solving word sense change. We build on ongoing effort at Språkbanken and our sentiment lexicon, SenSaldo, to tackle diachronic sentiment analysis for Swedish.
For all kinds of change targeted in this project, we will provide textual evidence to support our claims, e.g. , example sentences for each sense used to help users evaluate and understand the results. This is a prerequisite for uptake in the research community, in particular in the DHSS.
We envision several use cases that will help researchers and nonprofessional users to study language changes themselves, enabling them to search and explore archival content and improve downstream large-scale text mining applications. For researchers that are interested in language changes in general, our results will offer answers to what has changed as well as how and when it changed. It will also be possible to answer more complex questions like how is change in one word connected to changes in others in the same semantic field?
For researchers that have an interest in the resources but not necessarily in the changes themselves, e.g., researchers in DHSS, our methods will help to gather evidence for concepts by finding linked vocabulary and their senses, e.g. the word handikappad ’handicapped’ has been replaced over time (handikappad$\rightarrow$ funktionshindrad $\rightarrow$funktionsnedsatt$\rightarrow$ funktionsvariation). The replacement aims to remove negatively connotated senses, but from the continuous replacements, we know that these still catch up. Upon completion of this project, it will be possible to study the lexical replacements on the one hand, and tie it with semantic change. E.g. Does a new word like funktionshindrad take over a subset of the senses of the previous word at first and then later add the negative senses? How fast are the negative senses added for each lexical replacement and does it speed up with additional replacements? Do we include more or less in each sense or add new senses over time?
The methods developed in the project will be generally applicable, but our primary target language is Swedish with equal focus on historical and modern text. E.g. Swedish historical newspapers, Kubhist 1750-1925, books (the Literature bank), parliamentary data (SUC, SOU) and modern newspapers but also social media text where there is evidence of high linguistic diversity and creativity (Goel et al., 2016). This makes the availability of large amounts of Swedish text crucial to the project.
Språkbanken continuously collects texts written in Swedish, to date there is over 10 billion words of modern Swedish (e.g. fiction, news, politics and social media) and over one billion words of historical news materials. We will also use digital lexical resources, like SALDO, Svedbergs, Dahlin and SAOL.
We will replicate our research using English text such as the Corpus of Historical American English and Google books. We will extend previous studies and quantify hypothesis regarding lexical and semantic change, work that can feed back into our tools for quality assessment and improvement.