Nodalida 2023
Nodalida 2023
Abstract
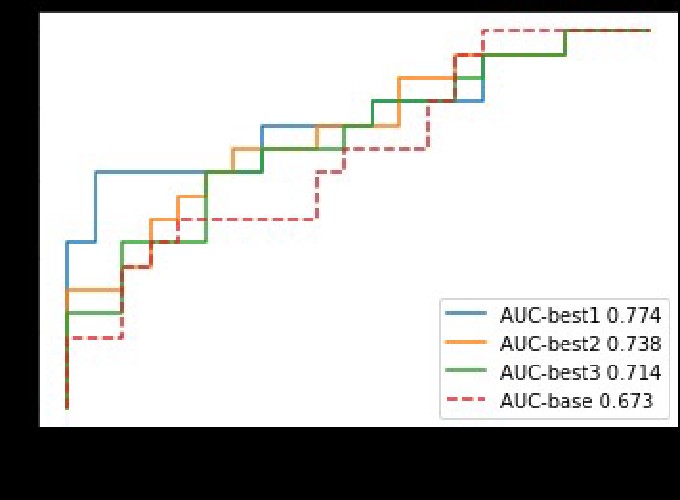
In this work we investigate the hypothesis that enriching contextualized models using fine-tuning tasks can improve their capacity to detect lexical semantic change (LSC). We include tasks aimed to capture both low-level linguistic information like part-of-speech tagging, as well as higher level (semantic) information. Through a series of analyses we demonstrate that certain combinations of fine-tuning tasks, like sentiment, syntactic information, and logical inference, bring large improvements to standard LSC models that are based only on standard language modeling. We test on the binary classification and ranking tasks of SemEval-2020 Task 1 and evaluate using both permutation tests and under transfer-learning scenarios.
Publication
The Finer They Get: Combining Fine-Tuned Models For Better Semantic Change Detection
Date
May, 2023
Links